
파이썬의 다중 상속
파이썬 다중 상속과 믹스인
파이썬 다중 상속
파이썬은 다중 상속을 지원합니다.
다중 상속이란 여러 클래스들을 상속받을 수 있는 것으로, 아래와 같은 형태로 사용합니다.
class SampleClass(ParentClass1, ParentClass2):
...
다중 상속은 제대로 사용된다면 편리하지만, 부적절하게 사용되는 경우 큰 문제를 유발할 수 있습니다.
따라서 다중 상속을 올바르게 사용하기 위한 패턴들에 대한 공부가 필요합니다.
따라서 이번 포스팅에서는
- 다중 상속 시에 메서드 결정 순서(MRO)가 어떻게 되는 지와
- 다중 상속을 적절히 사용하기 위한 믹스인(mixin)에 대해 알아보도록 하겠습니다.
다중 싱속 시 메서드 결정 순서(MRO)
어떠한 클래스가 여러 클래스들을 상속받은 경우를 생각해보도록 하겠습니다.
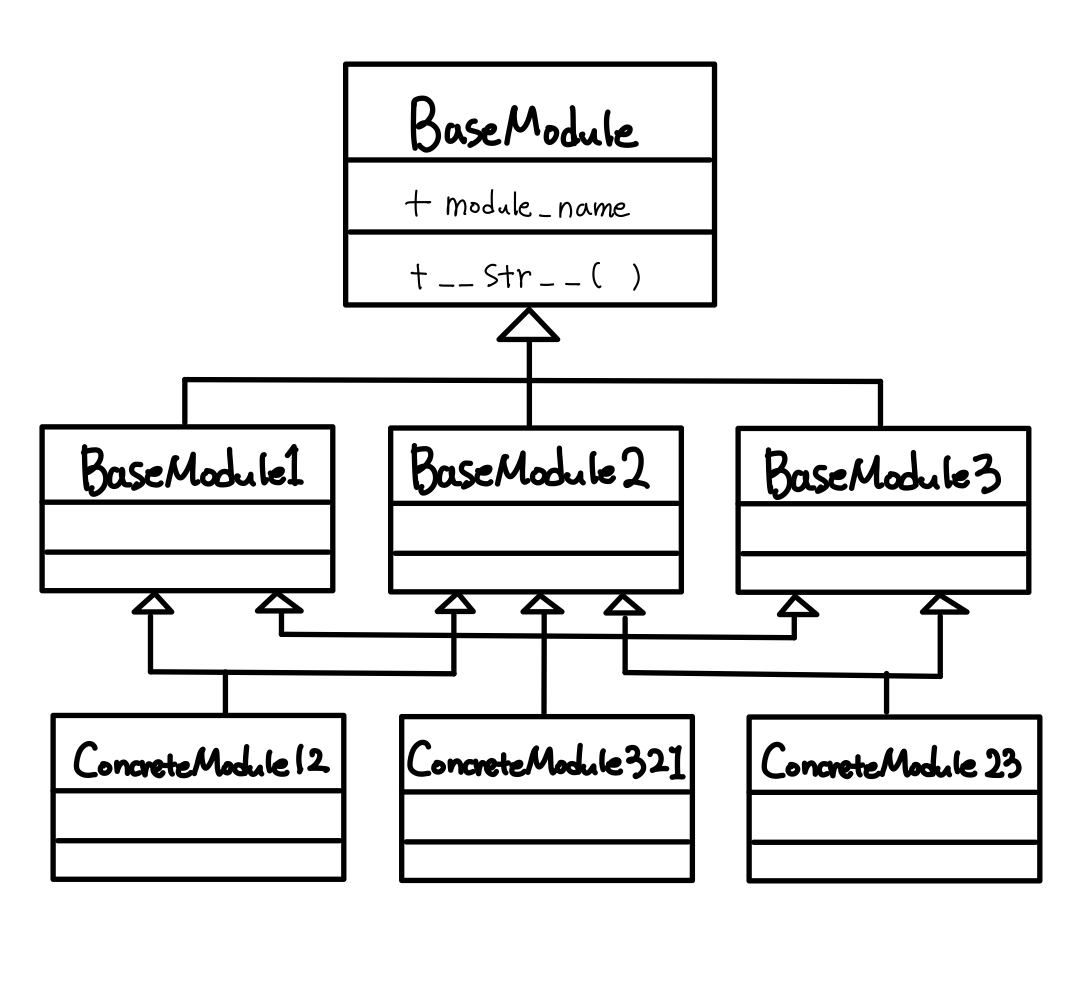
최상단에 BaseModule이 있고, BaseModule을 상속받은 BaseModule1, BaseModule2, BaseModule3이 있다고 합시다.
추가적으로 다중상속을 받는 클래스들을 생성할 것인데, 해당 클래스들은 아래와 같습니다.
- ConcreteModule12 클래스: BaseModule1, BaseModule2 상속
- ConcreteModule321 클래스: BaseModule3, BaseModule2, BaseModule1 상속
- ConcreteModule23 클래스: BaseModule2, BaseModule3 상속
클래스 다이어그램은 아래와 같습니다.
각 클래스 코드를 작성하면 아래의 코드와 같습니다.
class BaseModule:
module_name = "base"
def __init__(self, explanation):
self.explanation = explanation
def __str__(self):
return f"{self.module_name}: {self.explanation}"
class BaseModule1(BaseModule):
module_name = "module-1"
class BaseModule2(BaseModule):
module_name = "module-2"
class BaseModule3(BaseModule):
module_name = "module-3"
class ConcreteModule12(BaseModule1, BaseModule2):
"""BaseModule1 + BaseModue2"""
class ConcreteModule23(BaseModule2, BaseModule3):
"""BaseModule2 + BaseModue3"""
class ConcreteModule321(BaseModule3, BaseModule2, BaseModule1):
"""BaseModule3 + BaseModue2"""
BaseModule은 module_name이라는 속성과 __str__() 메서드를 구현하였습니다.
BaseModule1, BaseModule2, BaseModule3 클래스는 BaseModule을 상속받았고, 각자 module_name 속성을 재정의하였습니다.
그리고 ConcreteModule들은 따로 재정의한 속성이나 메서드가 없습니다.
이런 구성에서 ConcreteModule의 __str__() 메서드를 호출하면 어떻게 될까요? ConcreteModule12 같은 경우 BaseModule1, BaseModule2를 상속했으므로 둘 중 어떤 클래스의 module_name 속성값을 출력할 지 모호합니다.
에러가 날 것 같지만, 막상 실행해보면 에러가 나지는 않습니다.
print(str(ConcreteModule12("when BaseModule 1 is extended first")))
# 결과: module-1: when BaseModule 1 is extended first
print(str(ConcreteModule23("when BaseModule 2 is extended first")))
# 결과: module-2: when BaseModule 2 is extended first
print(str(ConcreteModule321("when BaseModule 3 is extended first")))
# 결과: module-3: when BaseModule 3 is extended first
이는 파이썬이 MRO 라는 알고리즘을 사용해서 충돌을 해결하기 때문입니다.
직접 클래스로부터 결정 순서를 확인할 수도 있습니다.
print("ConcreteModule12:", [cls.__name__ for cls in ConcreteModule12.mro()])
# 결과: ConcreteModule12: ['ConcreteModule12', 'BaseModule1', 'BaseModule2', 'BaseModule', 'object']
print("ConcreteModule23:", [cls.__name__ for cls in ConcreteModule23.mro()])
# 결과: ConcreteModule23: ['ConcreteModule23', 'BaseModule2', 'BaseModule3', 'BaseModule', 'object']
print("ConcreteModule321:", [cls.__name__ for cls in ConcreteModule321.mro()])
# 결과: ConcreteModule321: ['ConcreteModule321', 'BaseModule3', 'BaseModule2', 'BaseModule1', 'BaseModule', 'object']
결과를 확인해보면 메서드 충돌이 일어날 것 같을 때 먼저 상속된 순서일수록 우선순위가 높은 것을 확인할 수 있습니다.
믹스인 (Mixin)
믹스인은 다중 상속의 형태로 사용되며, 해당 클래스내에서 다른 클래스를 사용하여 동작할 수 있도록 만들어놓은 형태입니다.
상속의 경우를 생각해보면 공통적인 기능을 부모 클래스에 정의하고, 특수하거나 추가되는 기능을 자식 클래스에서 정의하여 동작하게 만들었습니다.
mixin의 경우에는 상속과 다르게 특정 클래스에서 처리하는 일에 부가적인 일을 추가적으로 끼워넣어 처리하고 싶을 때 사용합니다.
따라서 mixin은 다양한 기능이 조합되어야 하는 경우에 많이 사용합니다.
문자열을 Tokenizing하는 경우를 예시 코드로 작성해 mixin에 대해 더 자세히 알아보도록 하겠습니다.
다음과 같이 "-" 문자열을 기준으로 string을 tokenizing할 때 사용되는 BaseTokenizer가 있습니다.
class BaseTokenizer:
def __init__(self, str_token):
self.str_token = str_token
def __iter__(self):
yield from self.str_token.split("-")
만약 "-" 를 기준으로 문자열을 토크나이징 하고 싶은데 토크나이징된 결과값을 대문자로 바꾸고 싶다면 어떻게 구현하는 것이 좋을까요?
Tokenizer라는 클래스를 생성하고, 해당 클래스에서 __iter__() 함수를 오버라이딩 해서 재정의해도 구현이 되기는 합니다.
class TokenizerWithoutMixin(BaseTokenizer):
def __iter__(self):
yield from [token.upper() for token in self.str_token.split("-")]
그러나 위의 클래스는 Tokenizer입니다.
Tokenizer에서 토크나이징이 아닌 uppercase 기능을 수행하는 것은 조금 어색합니다.
따라서 대문자 변환 기능을 가진 Mixin을 추가해보도록 하겠습니다.
class UpperIterableMixin:
def __iter__(self):
yield from map(str.upper, super().__iter__())
UpperIterableMixin 클래스를 함께 상속받은 새로운 Tokenizer 클래스 코드는 다음과 같습니다.
class Tokenizer(UpperIterableMixin, BaseTokenizer):
pass
이 Tokenizer 클래스를 이용해 문자열을 Tokeninzing 해보겠습니다.
example_str = "ab/c-d/e-f/gh-ij/klm-nop"
tk1 = Tokenizer(example_str)
print("separate delimiter is '-'\n", list(tk1))
# 결과 ['AB/C', 'D/E', 'F/GH', 'IJ/KLM', 'NOP']
추가적으로 다른 기능을 가진 클래스도 구현해보도록 하겠습니다.
구현할 클래스는 입력받은 문자열에서 알파벳을 뺀 다른 문자열을 없애주는 기능을 가진 클래스로 역시 믹스인으로 이용해볼 것입니다.
import re
class SubtractStrExceptAlphabetMixin:
def __iter__(self):
yield from [re.sub(r'[^a-zA-Z]', '', tokenized_str) for tokenized_str in super().__iter__()]
class OnlyAlphabetTokenizer(SubtractStrExceptAlphabetMixin, BaseTokenizer):
pass
if __name__ == "__main"
tk = OnlyAlphabetTokenizer(example_str)
print("separate delimiter is '-' and remove other character except alphabet\n", list(tk))
# 결과 ['abc', 'de', 'fgh', 'ijklm', 'nop']
마지막으로 SubtractStrExceptAlphabetMixin 클래스와 UpperIterableMixin 클래스를 모두 사용하는 클래스를 구현해보도록 하겠습니다.
class OnlyUppercaseAlphabetTokenizer(UpperIterableMixin, SubtractStrExceptAlphabetMixin, BaseTokenizer):
pass
if __name__ == "__main__":
tk = OnlyUppercaseAlphabetTokenizer(example_str)
print("separate delimiter is '-' and remove other character except alphabet and change result to uppercase\n", list(tk))
# 결과: ['ABC', 'DE', 'FGH', 'IJKLM', 'NOP']
이처럼 다양한 기능을 추가해야하는 경우 믹스인을 사용해 다중상속을 적절히 활용할 수 있습니다.