
Kubernetes Pod
쿠버네티스 Pod
Pod이란?
Pod는 여러 컨테이너를 감싸고 있는 콩껍질 같다고 생각할 수 있습니다.
이 때 pod는 노드에서 컨테이너를 실행하기 위한 가장 기본적인 배포 단위입니다.
여러 노드에 1개 이상의 Pod를 분산하여 배포/실행할 수 있는데요, 이 때 다른 노드에 배포하기 위해 복제된 Pod를 Pod Replicas라고 부릅니다.
Pod 특징
쿠버네티스는 pod를 생성할 때 노드에서 유일한 IP를 할당하는데, 이를 통해 서버를 분리하여 사용하는 듯한 효과를 누릴 수 있습니다.
서로 다른 ip 주소를 사용하므로 pod에서 다른 pod으로의 통신을 원한다면 다른 pod의 ip를 사용하여 통신할 수 있습니다.
pod를 간략하게 그린 구조는 아래 그림과 같습니다.
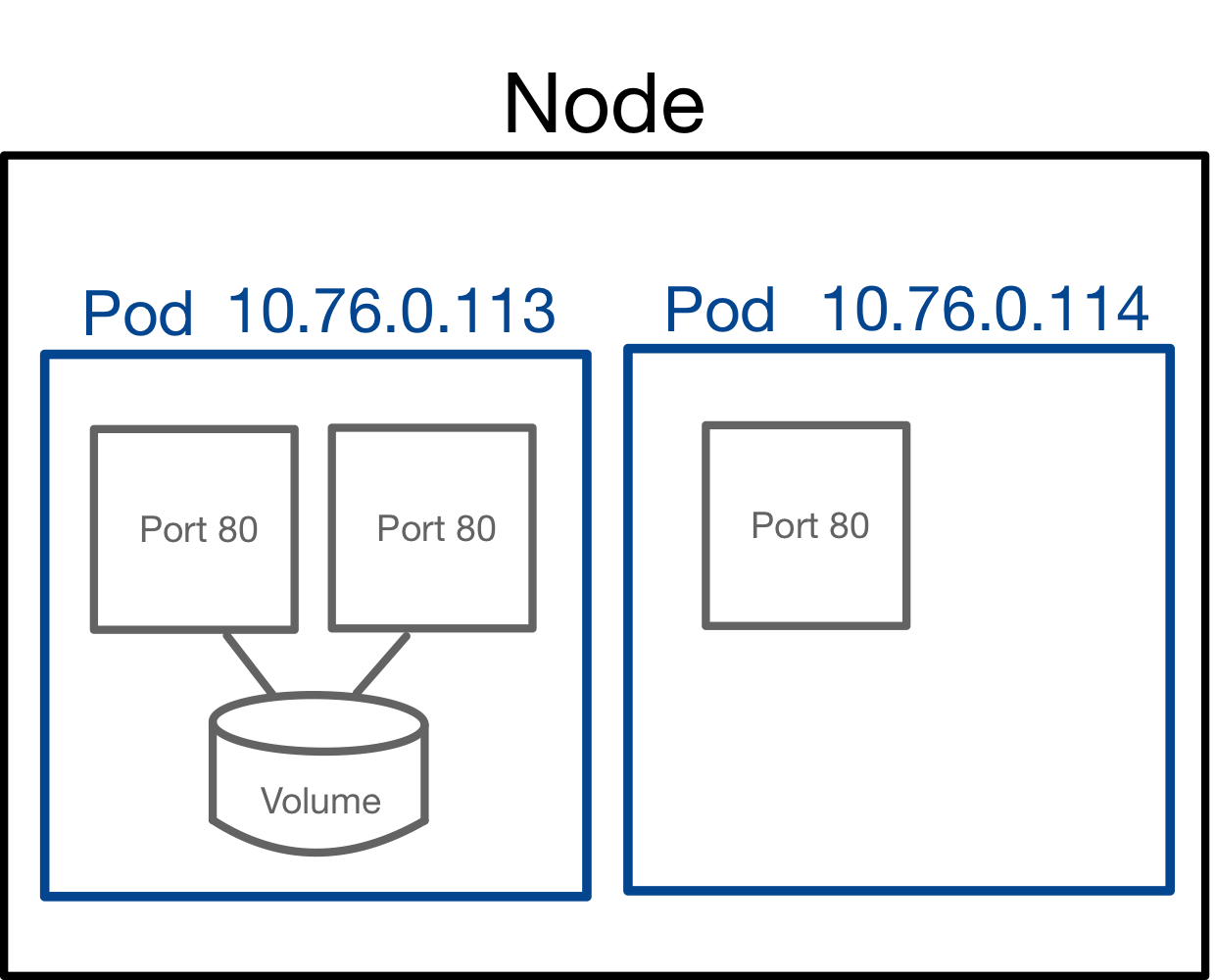
또한 하나의 pod 내에 있는 컨테이너들끼리는 같은 서버에 있는 것처럼 동작하므로 localhost로 통신할 수 있습니다.
이 때 포트 충돌이 나면 안되므로, pod내의 컨테이너들끼리는 동일 포트를 사용하지 않도록 유의해야합니다.
pod 내에는 볼륨을 둘 수 있는데요, 볼륨은 pod 내의 여러 컨테이너들이 공유해서 사용할 수 있습니다.
Pod과 Pod의 통신, Pod 내의 컨테이너끼리의 통신
Pod 마다 부여된 유일한 IP는 클러스터 안에서만 접근 가능합니다.
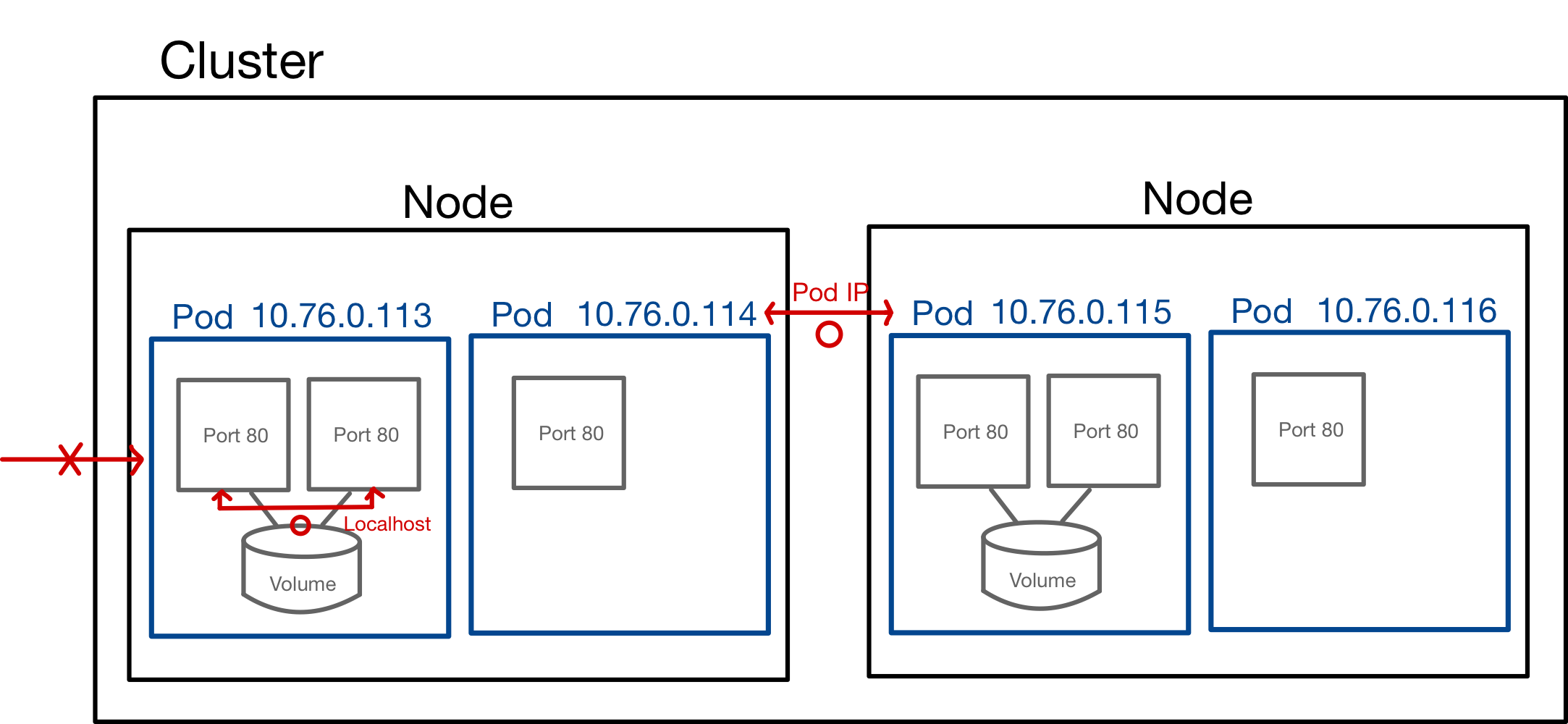
위의 그림처럼 클러스터 내부에서는 pod ip를 통해 서로 통신할 수 있지만, 외부에서는 pod ip를 가지고 트래픽을 전송할 수 없습니다
참고로 말하자면, 외부의 트래픽을 받기 위해서는 Service나 Ingressor 같은 다른 쿠퍼네티스 오브젝트의 도움이 필요합니다.
Pod 스케일 아웃, Container 설계
Pod 단위 배포
쿠버네티스에서는 Pod를 여러 노드에 분산시켜서 실행할 수 있는 방법을 제공하고 있습니다.
Pod 복제본의 개수 조정은 kubectl scale이라는 명령어를 통해 가능합니다.
kubectl scale deployment myapp --replicas=3
위의 명령어는 kubernetes를 이용하여 myapp이라는 어플리케이션을 3개 배포하라는 의미입니다.
Pod과 Container 설계
Pod 내부의 Container를 어떻게 배포할 지 설정할 때는 여러 사항을 고려하여 정하게 됩니다.
각 조건 및 상황에 따라 Pod:Container를 1:1로 배포할 지 혹은 1:N으로 배포할 지를 결정하게 됩니다.
[고려할 사항]
- 컨테이너들의 라이프사이클이 같은가?
- Pod의 라이프사이클 = 컨테이너들의 라이프사이클
- 컨테이너 A가 종료되었을 때 컨테이너 B의 실행이 의미가 있는 지 확인해보기
- e.g. 컨테이너 A는 애플리케이션이고 컨테이너 B는 A에 대한 로그 수집기라면 컨테이너 A가 종료되었을 때 컨테이너 B의 실행은 의미가 없습니다.
- 이런 경우는 각 컨테이너의 라이프사이클이 동일하므로 하나의 pod 안에 컨테이너들을 묶어둘 수 있습니다.
- 스케일 요구 사항이 같은가?
- 트래픽 관점) 서로 다른 트래픽을 갖는 서비스를 하나의 pod로 구성하면 높은 트래픽을 갖는 서비스의 스케일 아웃을 위해 작은 트래픽의 서비스까지 의미없이 스케일 아웃이 될 수 있습니다.
- 웹서버 vs 데이터베이스) 스케일링 방법이 다를 뿐더러 데이터베이스는 스케일링이 굉장히 까다롭기 때문에 하나의 pod으로 구성하기 어렵습니다.
- 인프라 활용도가 높은가?
- pod를 크게 설계하면 노드에 자리가 많이 남아있어야 배포가 가능하므로, 적절한 크기로 각 노드의 빈 자리에 새로 배포하기 좋게 pod를 설계하는 것이 좋습니다.
pod는 굉장히 빈번하게 내려갔다 올라오므로, 서로 다른 컨테이너를 하나의 pod 내에 구성하기 보다는 pod와 컨테이너를 1:1로 구성하기를 추천합니다.
Pod가 노드에 배포되는 과정과 클러스터 구성 요소별 역할
pod를 배포하기 위해 동작하는 구성 요소들은 아래 그림과 같습니다.

Pod가 노드에 배포되는 과정은 아래와 같습니다.
- 사용자로부터
Master Node의API Server가 pod 배포 요청을 수락합니다. - 전달받은 요청은
Replication Controller나Scheduler등 쿠버네티스의 여러 구성 요소에 이벤트 형식으로 전달됩니다. Replication Controller가 요청 받은 수와 현재 구동되고 있는 pod 개수의 차이를 확인하고 차이만큼의 pod 생성 요청을API Server에 보냅니다.- 생성 요청을 받은 pod은 아직 배포되지 않았기 때문에 Node 정보가 없는데, Scheduler에서 Node 정보가 없는 Pod만 골라 해당 pod를 배포하기 적절한 Node를 찾고, pod를 업데이트 합니다.
- 위의 단계에서 pod를 배포하기 위해 선택된 특정
worker node의kubelet은 자신의worker node에 할당받은 pod에 대한 이벤트를 수신하게 됩니다. - 실제로 pod를 생성하고 필요한 이미지를 다운받는 등의 일은
worker node의container runtime에서 작동합니다. - 예기치 못한 일로 인해 컨테이너 실행이 실패하면,
kubelet은 주기적으로 container로health check를 보내고 있기 때문에 응답으로 받은 상태를API Server에 보내며 쿠버네티스 상에서 pod가 정상적으로 동작할 수 있도록 역할을 수행합니다.
Pod 오브젝트 표현 방법
Pod 오브젝트 생성 요청을 보내기 위해 오브젝트 표현 방법을 알아보도록 하겠습니다.
기본적으로 필요한 속성은 apiVersion, kind, metadata, spec 네 가지 이며 각자 세부 구현 사항은 아래와 같습니다.
apiVersion: v1 # Kubernetes API 버전
kind: pod # 오브젝트 타입
metadata: # 오브젝트를 식별하기 위한 정보
name: kube-examle # 오브젝트 이름
labels: # 오브젝트 집합을 구할 때 사용할 이름표
app: kube-example
project: kubernetes_study
spec: # 사용자가 원하는 오브젝트의 상태
nodeSelector: # Pod를 배포할 노드
containers: # Pod 안에서 실행할 컨테이너 목록
volumes: # 컨테이너가 사용할 수 있는 볼륨 목록
spec
pod 오브젝트의 기본 속성 중 spec에 대한 부분을 더 자세히 알아보도록 하겠습니다.
nodeSelector
여러 노드 중에 gpu가 false인 노드와 gpu가 true인 노드가 있다고 할 때 특정 pod를 gpu가 true인 노드에만 배포하고 싶다면 아래와 같이 명세서를 작성합니다.
spec:
nodeSelector: # Pod를 배포할 노드를 선택
gpu: "true" # 노드 집합을 구하기 위한 식별자 (key-value 형태)
containers
파드 내에 생성할 컨테이너에 대한 내용은 아래와 같이 작성합니다.
spec:
containers: # 하나의 pod에 여러 container를 위치시킬 수 있으므로 리스트로 작성 가능
- name: kube-example # 컨테이너 이름
image: kube-example:1.0 # 도커 이미지 주소
imagePullPolicy: "Always" # 도커 이미지 다운로드 정책 (Always / IfNotPresent(로컬에 있으면 받지 않음) / Never(항상 받지 않음))
ports: # 여러 port가 선언 가능하므로 list로 선은
- containerPort: 80 # 통신에 사용할 컨테이너 포트 (expose된 포트)
컨테이너에서 사용할 환경 변수를 pod 오브젝트 내에 선언할 수도 있습니다.
spec:
containers:
- name: kube-example
image: kube-example:1.0
env:
- name: PROFILE # 환경변수 이름
value: production # 환경변수 값
- name: CONFIG_DIRECTORY
value: /config
- name: MESSAGE
value: This application is running on $(PROFILE) # 다른 환경변수 참조 가능
컨테이너에서 사용할 볼륨을 마운트하려고 할 때는 속성을 다음과 같이 표기합니다.
spec:
containers:
- name: kube-example
image: kube-example:1.0
volumeMounts: # 컨테이너에서 사용할 Pod 볼륨 목록
- name: html # Pod 볼륨 이름
mountPath: /var/html # 볼륨을 마운트할 컨테이너 내의 경로
- name: web-server
image: nginx
volumeMounts:
- name: html # 위와 동일한 html이라는 Pod 볼륨 사용
mountPath: /usr/share/nginx/html # 같은 볼륨을 참조하고 있지만 다른 경로로 마운트
readOnly: true
volumes
파드 내에 생성할 볼륨에 대한 내용은 아래와 같이 작성합니다.
spec:
containers:
volumes: # 컨테이너가 사용할 수 있는 볼륨 목록
- name: host-volume # 볼륨 이름
hostPath: # 볼륨의 타입 중 하나. 노드에 있는 파일이나 디렉토리를 마운트하려고 할 때 사용
path: /data/mysql
위에서 hostPath 라는 볼륨 타입을 사용했는데, 이 외에도 다른 볼륨 타입을 사용하고 싶다면 이 페이지에서 다양한 볼륨 타입을 확인할 수 있습니다.
Pod의 한계점과 보완 방법
실제로 운영 환경에서는 Pod 오브젝트만 가지고 서비스를 하기는 힘이 듭니다.
그 이유는 다음과 같습니다.
- Pod가 나도 모르는 사이에 종료될 수 있습니다.
- 한계) pod는 스스로 다시 복구(Self-Healing)될 수 없기 때문에 pod가 pod나 노드 문제로 종료된다면 다른 노드에 pod를 다시 배포하는 과정을 거쳐야 합니다.
- 보완) 사용자가 선언한 수만큼 pod를 유지해주기 위해
ReplicaSet오브젝트가 도입되었습니다.
- Pod IP는 외부에서 접근할 수 없고, 생성될 때마다 변경됩니다.
- 한계) 요청을 보내는 클라이언트 입장에서는 계속 ip를 추적해야하는 어려움이 있기 때문에 외부에서 접근할 수 있는 고정적인 단일 엔드포인트의 필요성이 생기게 됩니다.
- 보완) Pod 집합을 클러스터 외부로 노출하기 위한 엔드포인트 역할을 하는
Service오브젝트가 도입되었습니다.