
Kubernetes 기본 개념
쿠버네티스와 클러스터 동작 방식
쿠버네티스의 필요성
MSA
MSA란 마이크로서비스아키텍처(Micro Service Architecture)의 약자로, 작고 독립적인 여러 서비스들을 배포하는 것을 의미합니다.
기존의 많은 서비스들은 Monolithic Service, 즉 하나의 큰 서비스를 통해 배포되고 운영되어왔는데요, 이런 방식은 서비스의 규모가 커질수록 여러 문제를 낳게 됩니다.
<Monolithic Service의 단점>
- 특정 영역의 장애로 인해 서비스 전체가 영향을 받을 수 있습니다.
- 예) 트래픽이 특정 서비스에 몰렸을 때, 다른 서비스들도 함께 영향을 받음
- 배포 시간이 오래 걸립니다.
- 예) 하나의 큰 서비스이므로 코드의 양이 많고, 코드간의 의존도가 높아 수정에 대한 테스트 및 배포가 쉽지 않음
- Scale-out이 어렵습니다.
- 특정 부분에 트래픽이 높을 경우, 해당 부분만 scale-out 하는 것이 불가능하므로, 트래픽이 많지 않은 다른 부분까지도 scale-out 하게됨
- Framework 및 언어 사용이 제한됩니다.
- 하나의 서비스로 구성되므로, 언어 및 프레임워크를 다양하게 쓸 수 없고 한 가지로 통일하게 됨
이러한 Monolithic Service의 단점으로 인해 MSA가 도입되었으며, 많게는 수 백개의 작은 서비스로 하나의 큰 서비스를 분할해 개발/관리/배포 프로세스를 각각 따로 진행하게 되었습니다.
그러나 MSA로 서비스를 변환함에 따라 생기는 문제점들도 있었습니다.
<MSA 변환으로 인한 문제>
- 많은 서비스들을 사람이 직접 서버에 배포하고 하나하나 관리하기 어렵습니다.
- 각 서비스별 트래픽을 미리 예측하여 필요한만큼 배포하는 것이 쉽지 않습니다.
- 특정 서비스가 어떤 서버에서 실행되고 있는 지 알기가 어려우므로 문제 발생 시 복구 시간이 오래 걸립니다.
쿠버네티스
개발자가 애플리케이션 실행/배포 방법 명세서를 정의하면 쿠버네티스가 해당 사항을 반영하여 컨테이너로 애플리케이션을 배포하고, 실행되도록 하는 역할을 수행합니다.
즉, 쿠버네티스는 여러 개의 컨테이너화된 애플리케이션을 여러 서버(쿠버네티스 클러스터)에 자동으로 배포, 스케일링 및 관리해주는 오픈소스 시스템이라고 볼 수 있습니다.
MSA의 문제를 해결해줄 수 있는 쿠버네티스의 기능
- 자동화된 빈 패킹(bin packing): 각 컨테이너가 필요로하는 CPU, 메모리를 쿠버네티스에게 지시하면 쿠버네티스가 컨테이너를 노드에 맞추어서 리소스를 가장 잘 사용할 수 있게 해줍니다.
- 자동화된 복구(self-healing): 실패한 컨테이너를 재실행해줍니다. 컨테이너의 상태를 검사하여 응답이 없는 컨테이너를 종료하고, 이러한 과정을 자동화해줍니다.
- 자동화된 롤아웃, 롤백
- 롤아웃: 배포하는 과정을 의미합니다.
- 롤백: 문제 시 이전 버전으로 되돌리는 것을 의미합니다.
- 어떻게 롤아웃, 롤백할 지 원하는 상태를 서술하면 쿠버네티스가 설정한 속도에 따라 작업을 수행합니다.
- 이전 버전을 기억하기 때문에 간단한 명령어를 통해 쉽게 롤백이 가능합니다.
서비스 디스커버리
마이크로서비스아키텍처에서는 수많은 애플리케이션이 예고없이 종료 & 재시작됩니다.
이 때 애플리케이션이 실행되는 노드는 매번 바뀌어 클라이언트가 IP를 알기 쉽지 않습니다.
따라서 중앙에 마이크로서비스들의 주소 목록을 관리하는 Service Registry 서버를 두어 주소를 관리합니다.
이 때 서비스가 등록되고 관리되는 과정은 아래와 같습니다.
- 마이크로 서비스 인스턴스를 service registry 서버에 register / cancel
- Service Registry 서버에서 주소 목록에 변경사항 반영
- 주기적으로 인스턴스가 살아있는 지 여부를 알리기 위해 Service Registry 서버에 heartbeat 전송
- heartbeat가 오지 않을 경우 registry 목록에서 제외
낙관적 동시성 제어
낙관적 동시성 제어는 리소스 충돌을 해결하기 위한 방법으로 주요 개념은 아래와 같습니다.
- 서로 다른 사용자가 같은 리소스를 조회
- 한 명의 사용자가 해당 리소스를 변경하여 저장 -> 변경사항 저장 성공
- 또 다른 사용자가 다시 해당 리소스를 변경하여 저장 -> 변경사항 저장 실패 (
이전에 조회된 리소스 버전 != 현재 쿠버네티스 리소스의 상태 버전이기 때문)
쿠버네티스 클러스터
- 클러스터: 여러 서버를 하나로 묶은 집합으로, 하나의 서버처럼 동작합니다.
- 쿠버네티스 클러스터: 애플리케이션 컨테이너를 배포하기 위한 서버 집합입니다. (여러 서버를 쿠버네티스가 관리하기 쉽도록 하나로 묶은 것)
쿠버네티스 클러스터의 구성
Master 노드
- 대장 노드
- Control Plane (제어판의 역할)
- 클러스터의 상태를 저장하고 관리합니다.
- etcd라는 key-value data store를 이용해 클러스터에 배포된 애플리케이션 실행 정보를 저장합니다.
- API Server를 포함하고 있어 REST API를 통해 외부의 요청을 받습니다.
- scheduler를 통해 노드 스케쥴링을 수행합니다.
- controller manager를 통해 사용자가 요청한 대로 컨테이너들이 운영되고있는 지를 감시하고, 일치하지 않는다면 API server를 통해 추가 리소스를 요청합니다.
Worker 노드
- 컨테이너 실행을 담당합니다
- kubelet이라는 프로세스가 동작하고 있습니다.
- 컨테이너 실행을 위한 Docker 등의 Container Runtime을 포함합니다.
- Worker node로 들어오는 트래픽을 pod로 전달하기 위해 kube-proxy라는 프로세스가 실행되고 있습니다.
“쿠버네티스에 애플리케이션 컨테이너를 배포한다”는 의미
= 쿠버네티스 오브젝트를 정의하기 위한 Manifest 파일을 작성해 마스터 노드에 있는 API Server에게 요청을 보내는 것을 의미합니다.
Manifest 파일
쿠버네티스 오브젝트를 생성하기 위한 필수 정보들을 작성한 파일
API Server의 역할
쿠버네티스의 API 서버는 옵저버 패턴처럼 동작합니다.
옵저버 패턴
구독하고자하는 이벤트를 하나의 중앙 장치에 등록해놓고, 이벤트가 발생할 때마다 이벤트에 대한 알림을 받는 패턴
즉, API 서버와 다른 컴포넌트들 (Controller Managers, Scheduler 등)의 동작 방식은 옵저버 패턴과 유사하게 이벤트가 발생했을 때 API 서버에 알림을 주고, 내용에 따라 API 서버가 적절하게 대응하는 형태입니다.
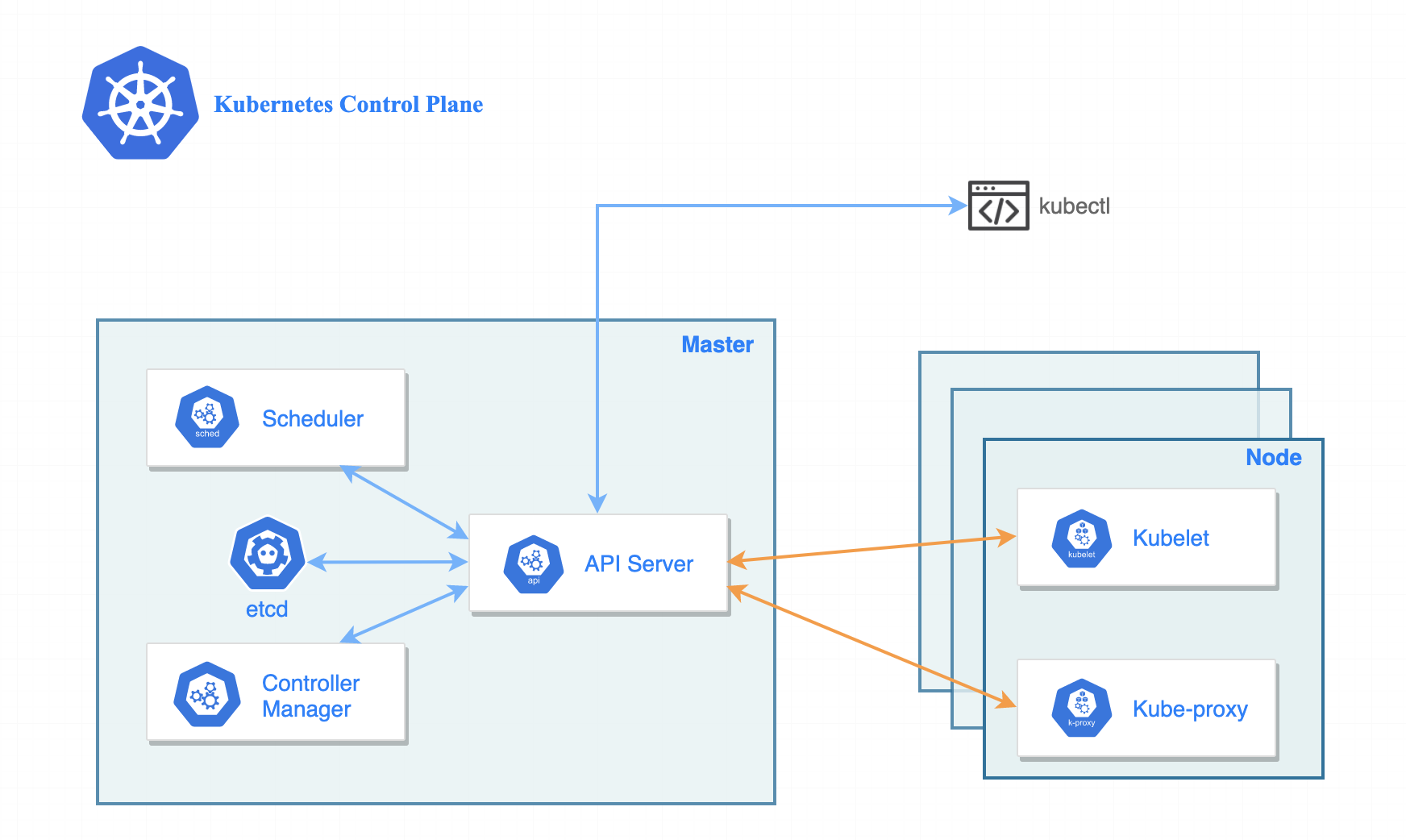
위의 그림을 참고하여 쿠버네티스에서 배포가 수행되는 과정에 대해 알아보도록 하겠습니다.
- kubectl을 통해 명령어를 개발자가 수행시키면 해당 명령은 HTTP POST Request로 변환되어 API Server에 도달합니다.
- API 서버는 들어온 요청을 기반으로 상태를 etcd라는 영구 저장소에 저장합니다.
- API 서버는 요청받은 이벤트를 Controller Manager에게 전달하고, Controller Manager는 다시 API 서버에 이벤트 수행을 위한 추가 리소스 요청 등을 보냅니다.
- API 서버는 pod 생성 요청을 받게되고, pod에 대한 설정 정보를 etcd에 저장합니다.
- Scheduler가 아직 노드에 반영되지 않은 pod를 읽어와 해당 pod를 배포할 최적의 Node를 선택합니다.
- Scheduler는 선택된 Node의 정보 변경에 대한 요청을 다시 API 서버에 보냅니다.
- API Server는 변경된 Node 정보를 다시 etcd에 저장합니다.
-> pod가 노드에 할당이 완료되는 시점 - pod가 할당된 Worker Node의 kubelet 프로세스에 배포할 pod가 있다는 이벤트가 전달됩니다.
-> kubelet은 컨테이너 생성 및 실행 명령을 내리거나 실행중인 컨테이너의 health check를 담당하는 역할을 가지고 있음 - kubelet이 docker(컨테이너 런타임이 도커인 경우)에 컨테이너 생성 및 실행 명령을 내려 배포를 진행합니다.
- kubelet은 컨테이너의 상태 및 리소스의 삭제를 API 서버에 보고합니다.
쿠버네티스 내에서 트래픽의 전달
쿠버네티스에서 트래픽은 kube-proxy를 이용해 전달됩니다.
각각의 worker node에는 kube-proxy들이 수행되고 있습니다.
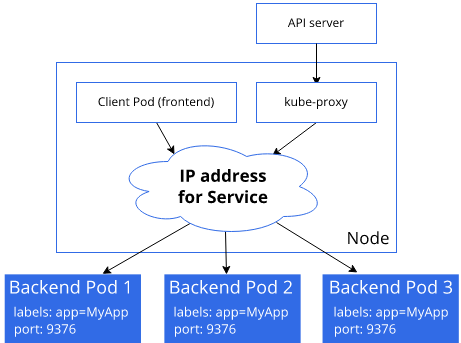
위의 그림을 토대로 예를 들어 API 서버에서 리소스의 엔드포인트를 추가하거나 변경하는 이벤트를 worker node에 전달했다고 하겠습니다.
그러면 pod에 ip들이 할당될 것이고, 할당된 ip 정보가 추가되면 kube-proxy가 그 정보를 감시하여 자신의 worker node에 있는 ip 테이블을 업데이트합니다.
따라서 kube-proxy는 해당 worker node로 새로운 트래픽이 들어왔을 때 그 클라이언트의 요청을 목적지로 연결하기 위한 역할을 제공합니다.